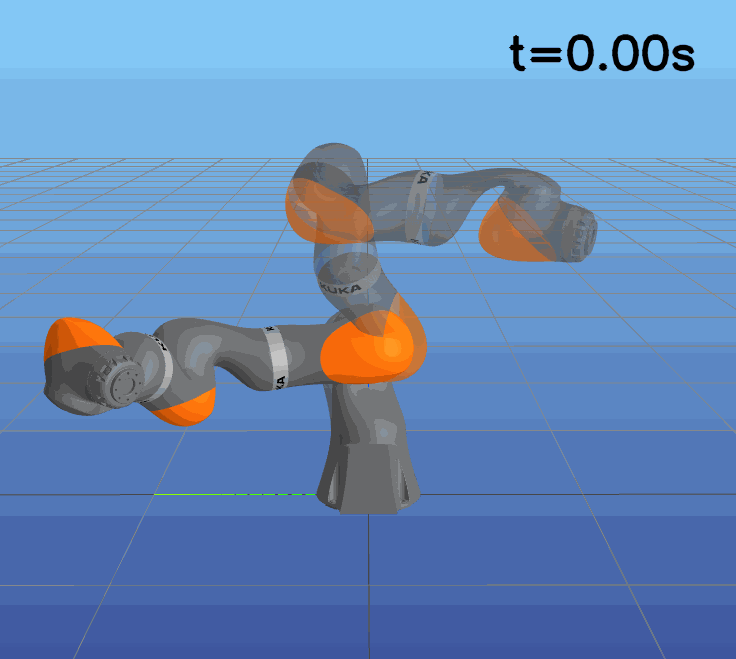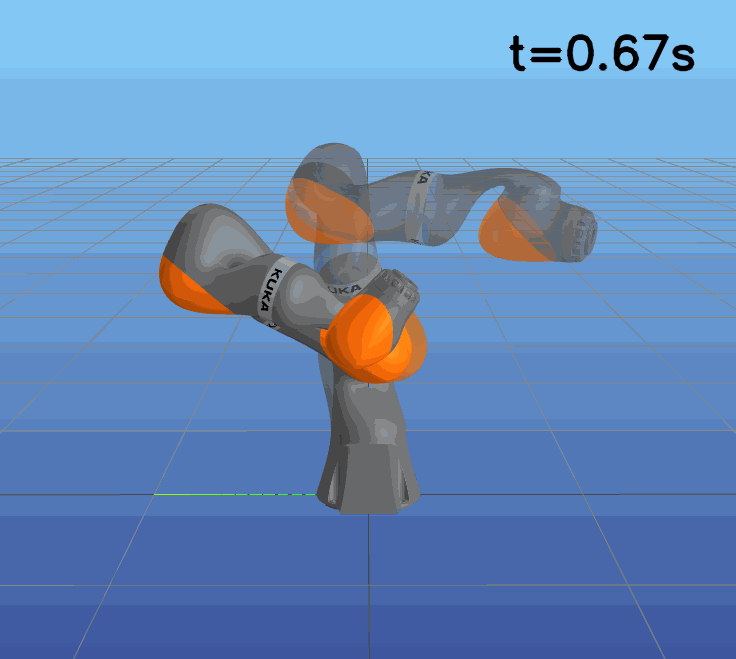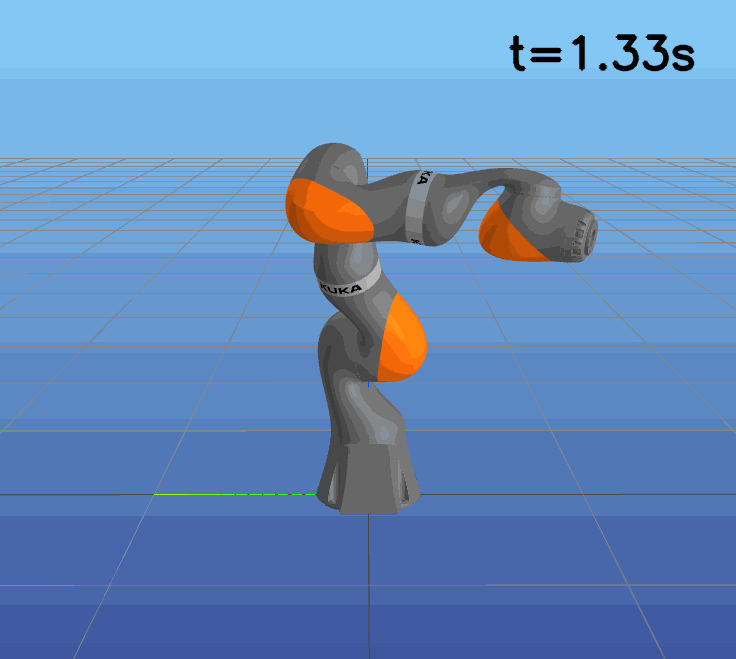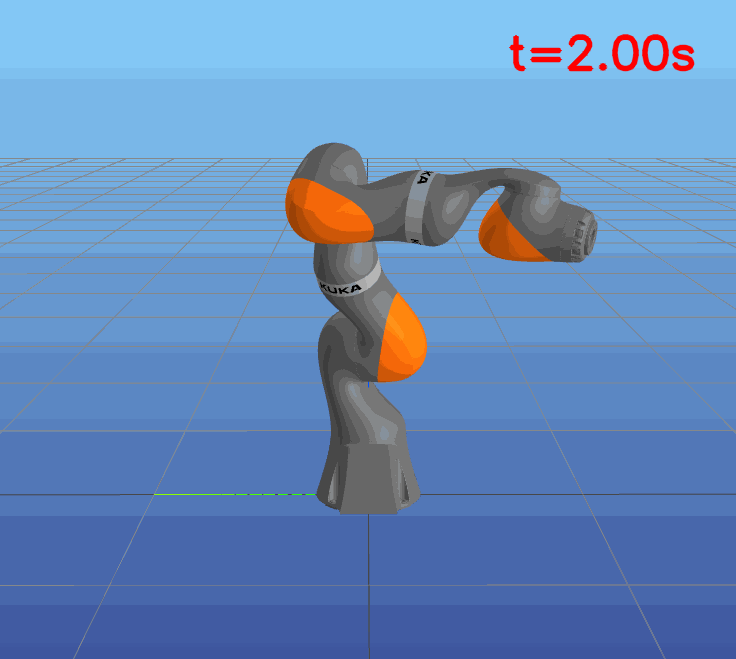
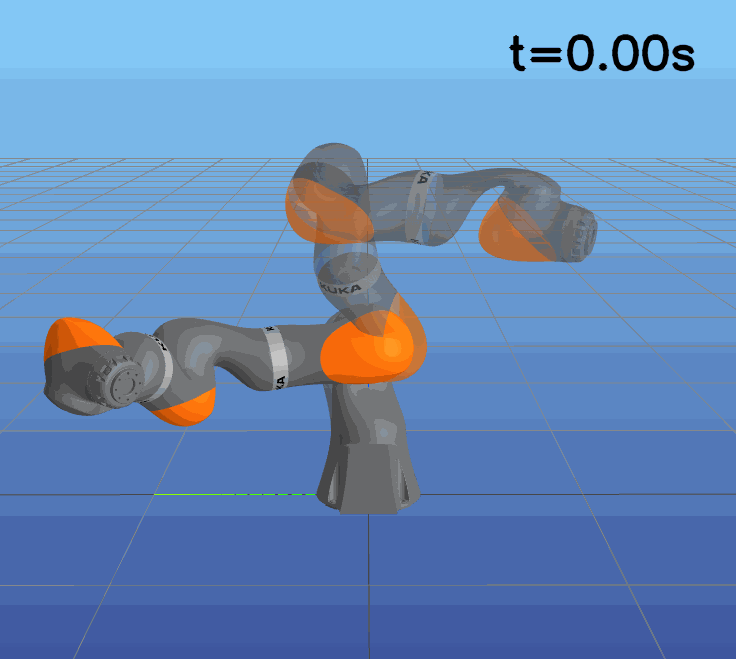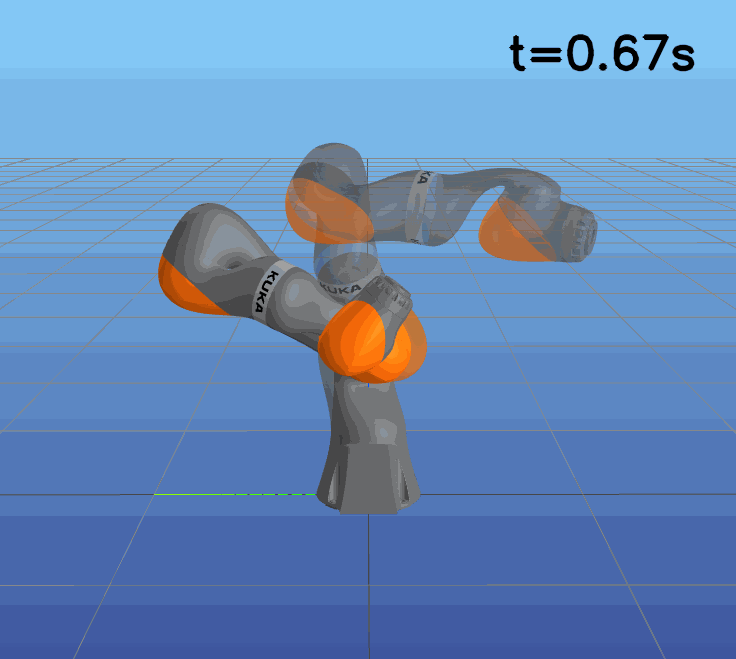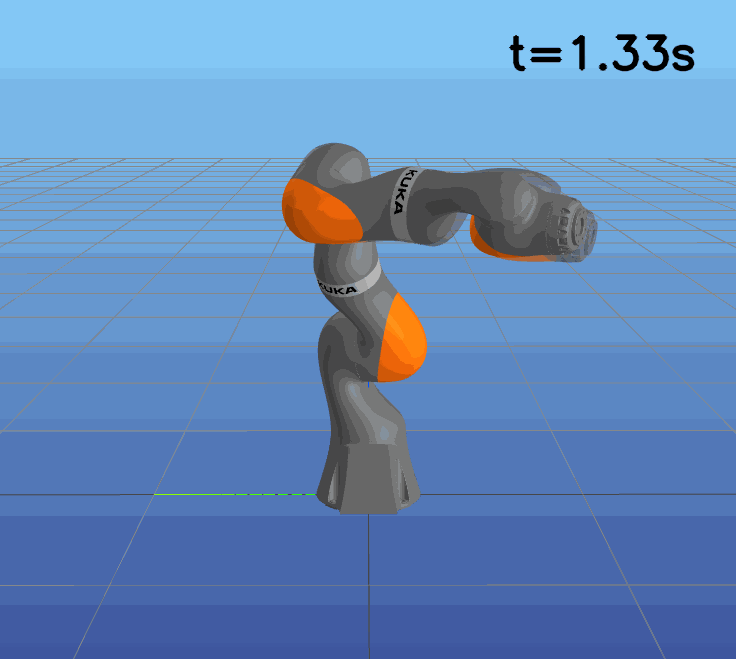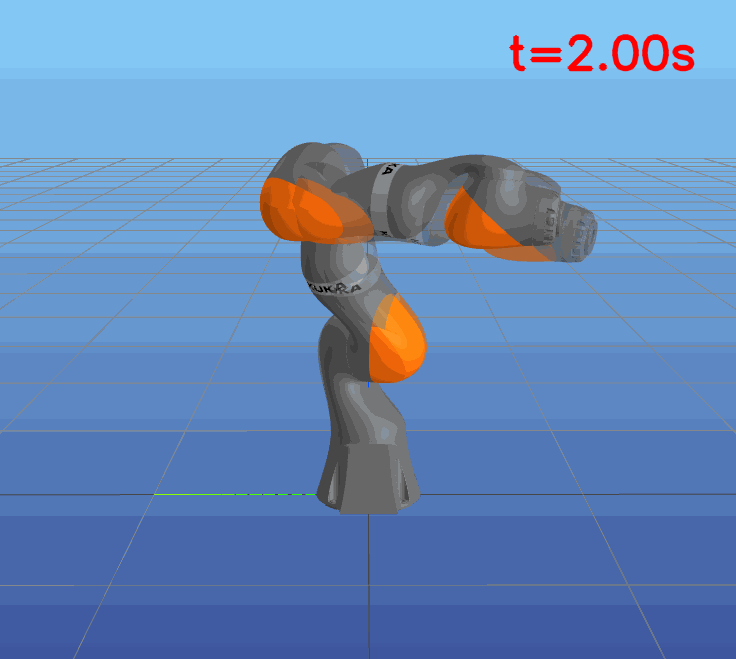
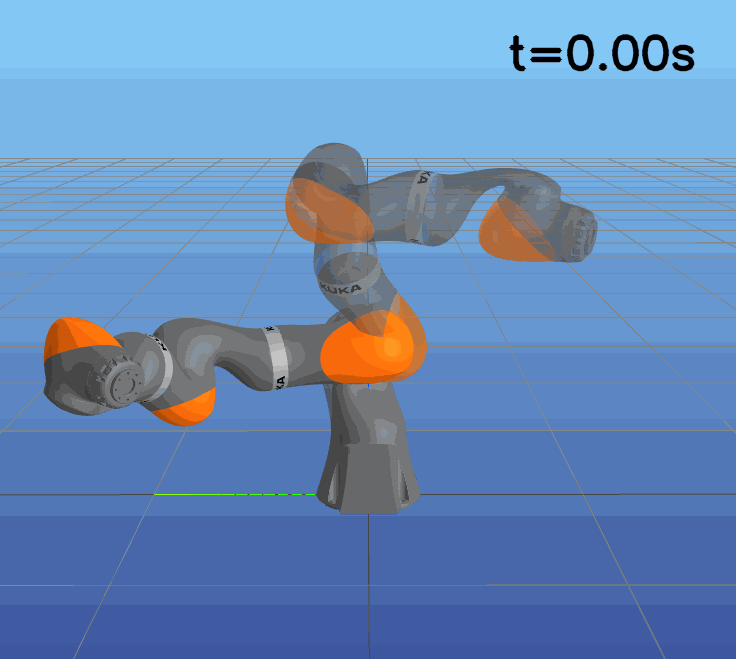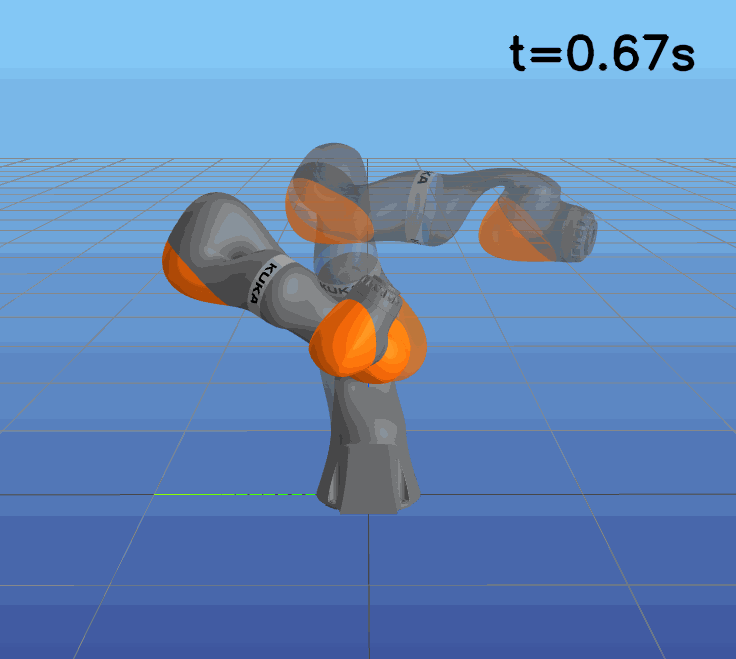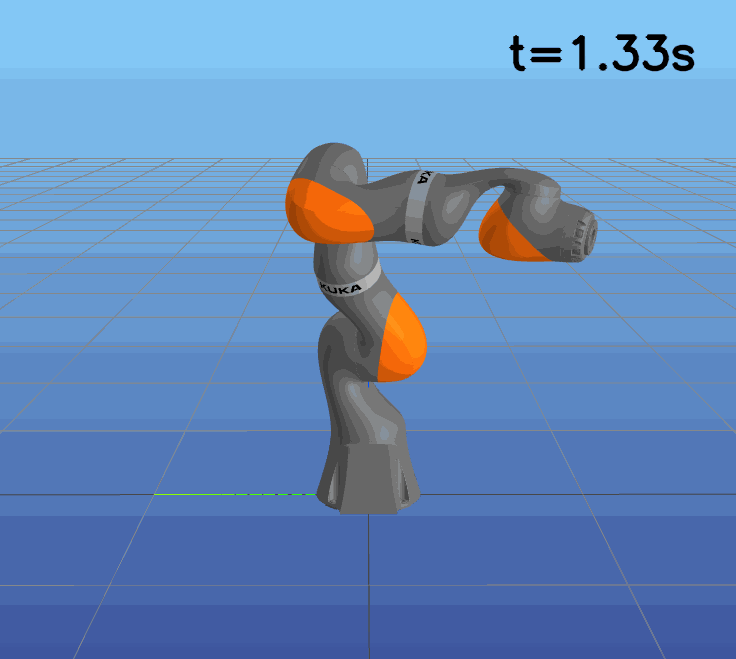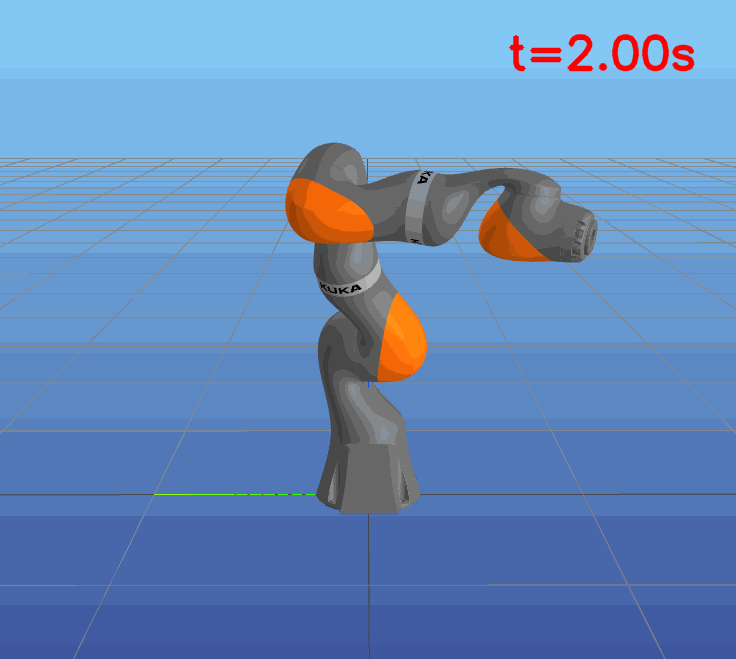
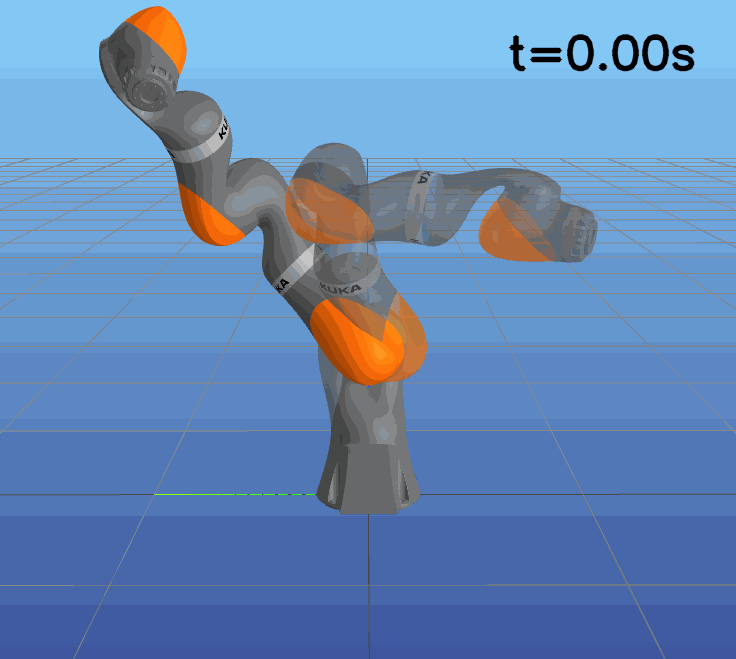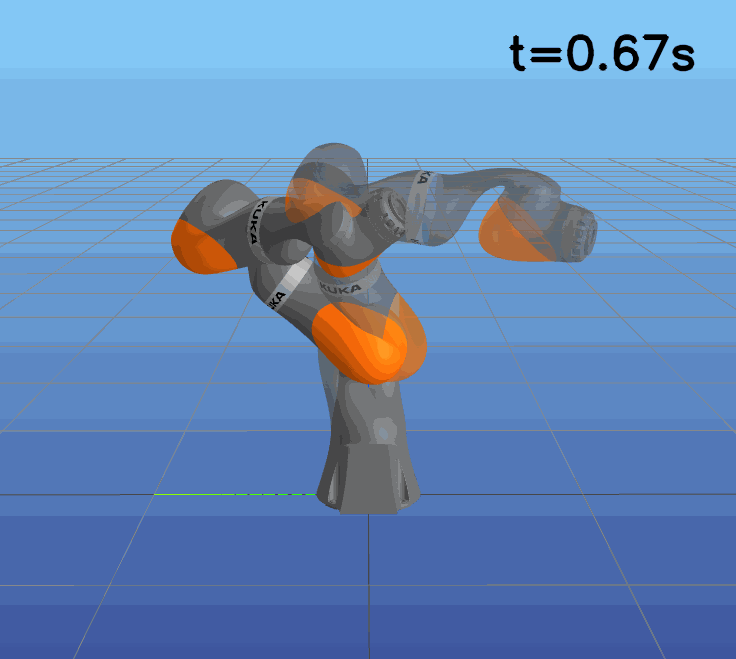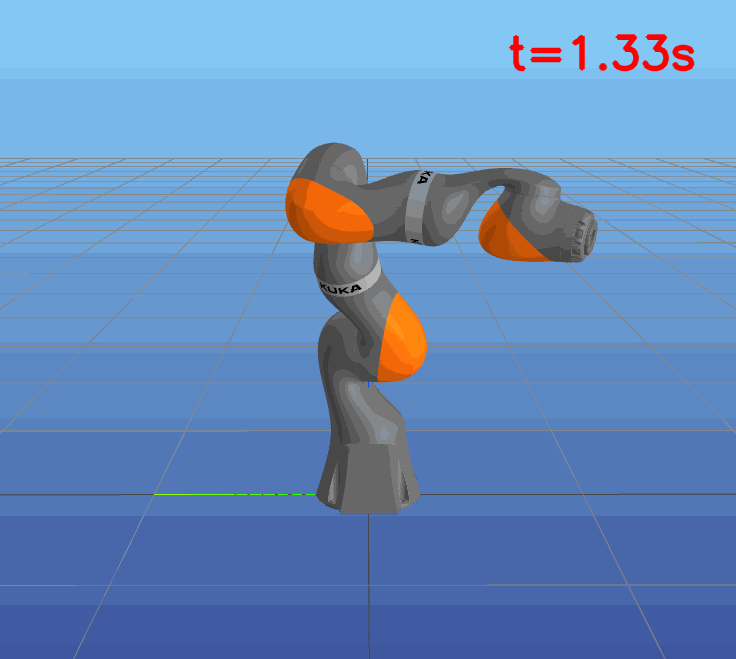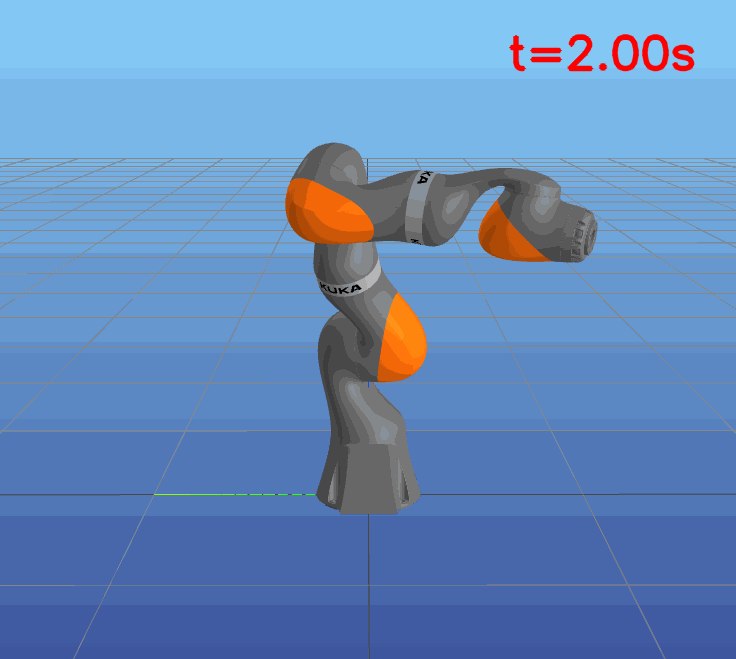
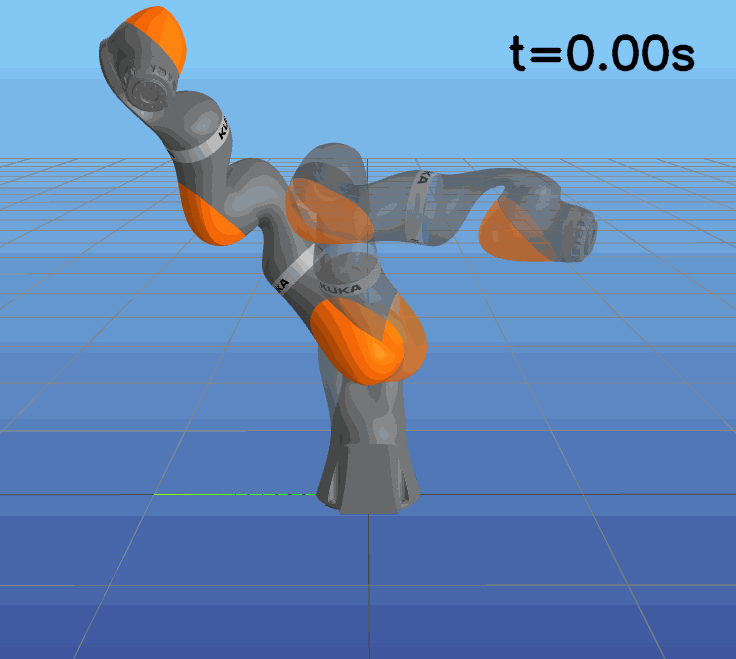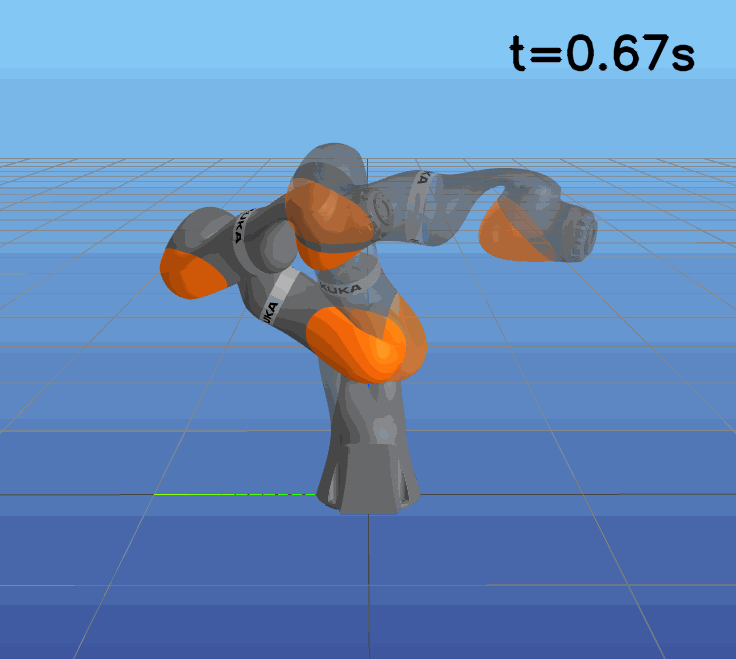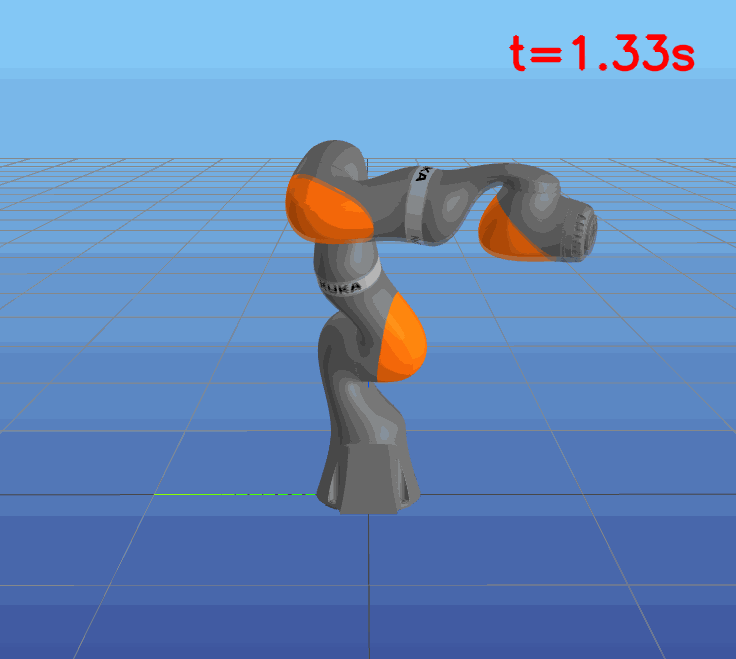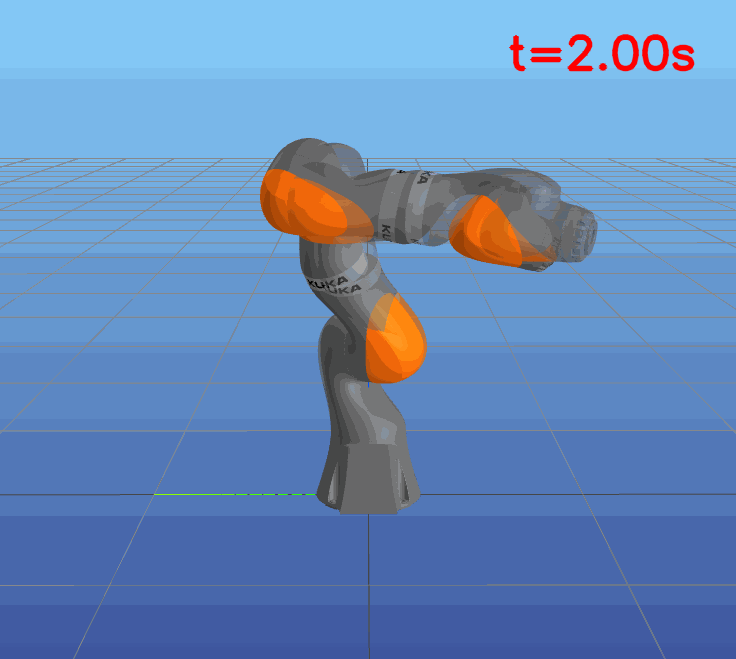
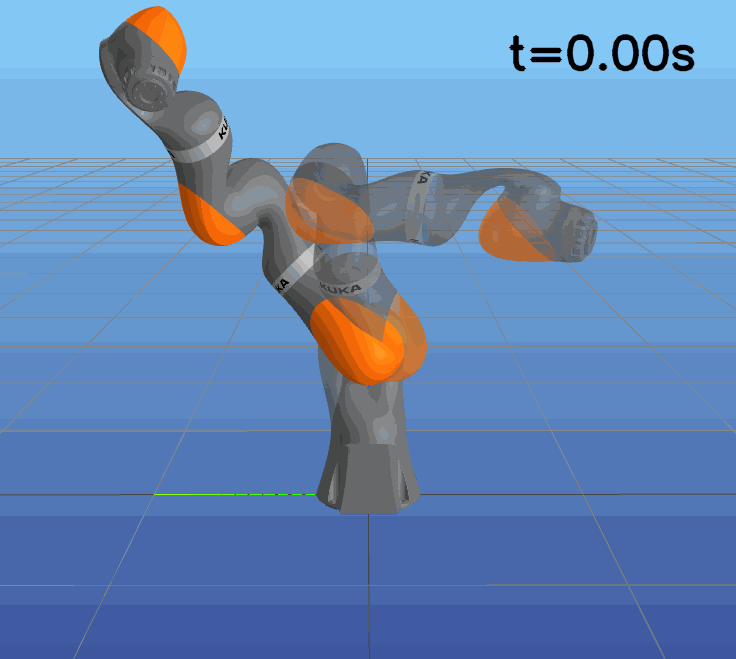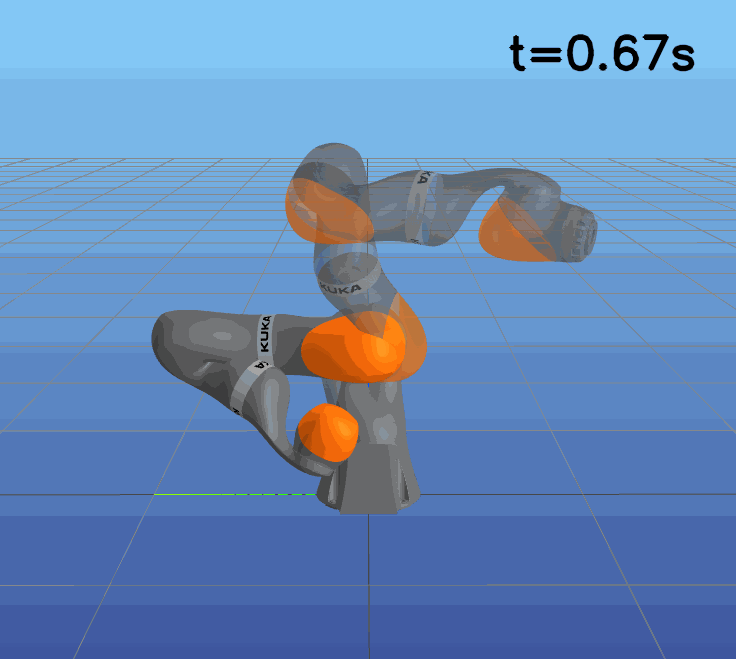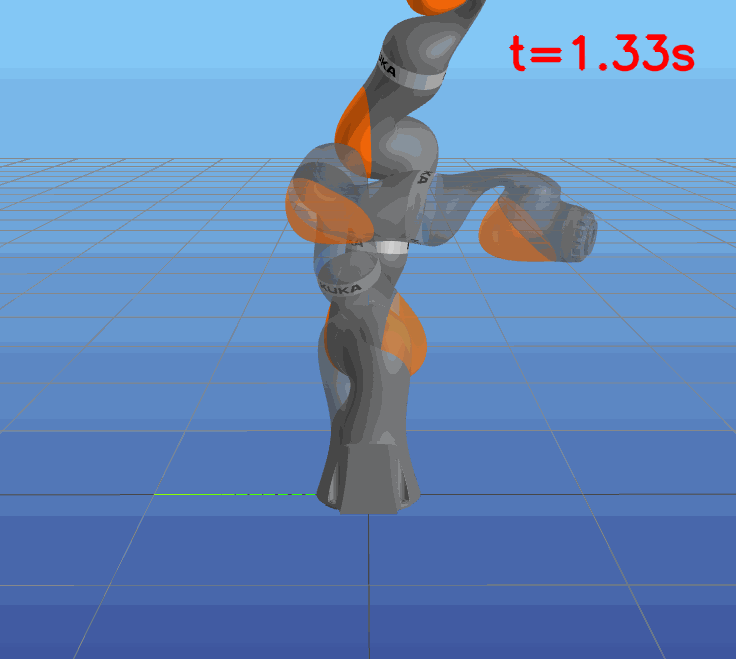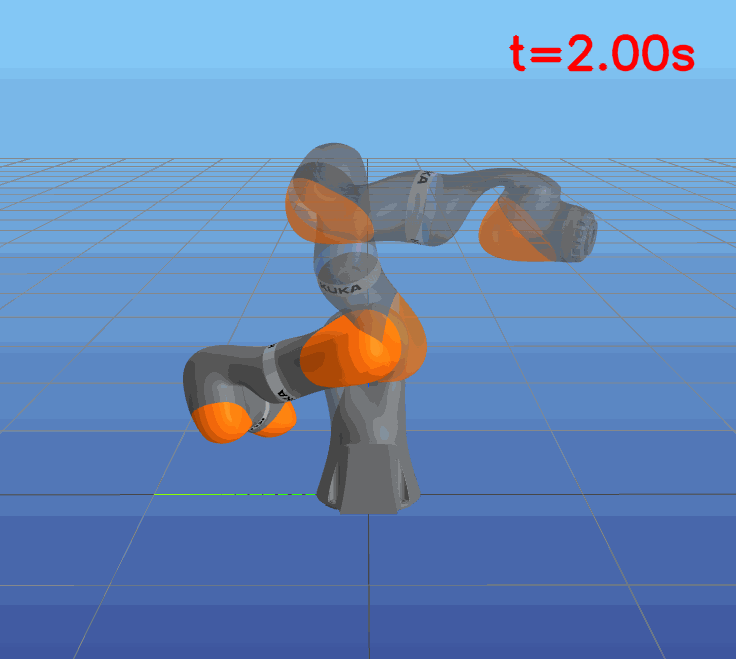
This paper presents a novel approach to learning free terminal time closed-loop control for robotic manipulation tasks, enabling dynamic adjustment of task duration and control inputs to enhance performance. We extend the supervised learning approach, namely solving selected optimal open-loop problems and utilizing them as training data for a policy network, to the free terminal time scenario. Three main challenges are addressed in this extension. First, we introduce a marching scheme that enhances the solution quality and increases the success rate of the open-loop solver by gradually refining time discretization. Second, we extend the QRnet in Nakamura-Zimmerer et al. (2021b) to the free terminal time setting to address discontinuity and improve stability at the terminal state. Third, we present a more automated version of the initial value problem (IVP) enhanced sampling method from previous work (Zhang et al., 2022) to adaptively update the training dataset, significantly improving its quality. By integrating these techniques, we develop a closed-loop policy that operates effectively over a broad domain with varying optimal time durations, achieving near globally optimal total costs.
@inproceedings{hu2025learning,
author = {Hu, Wei and Zhao, Yue and E, Weinan and Han, Jiequn and Long, Jihao},
title = {Learning Free Terminal Time Optimal Closed-loop Control of Manipulators},
booktitle = {Proceedings of the American Control Conference (ACC)},
year = {2025},
address = {Denver, CO, USA}
}